

The main topic of this article is to create your own topic model using BERT.
Let’s go through the steps from downloading the data to building the topics as below.
1. Data & Packages
For this example, we will use the famous 20 Newsgroups dataset which contains roughly 18000 newsgroups posts on 20 topics. Using Scikit-Learn, we can quickly download and prepare the data:

Note: To speed up training, you can select the subset train as it will decrease the number of posts you extract. Also if you want to apply topic modeling not on the entire document but on the paragraph level, I would suggest splitting your data before creating the embeddings.
2. Embedding
The very first step we have to do is converting the documents to numerical data. We use BERT for this purpose as it extracts different embeddings based on the context of the word. Not only that, there are many pre-trained models available ready to be used.
Install the package with pip install sentence-transformers before generating the document embeddings. If you run into issues installing this package, then it is worth installing pytorch first.
Then, run the following code to transform your documents in 512-dimensional vectors:

NOTE: Since transformer models have a token limit, you might run into some errors when inputting large documents. In that case, you could consider splitting documents into paragraphs.
3. Clustering
We want to make sure that documents with similar topics are clustered together such that we can find the topics within these clusters. Before doing so, we first need to lower the dimensionality of the embeddings as many clustering algorithms handle high dimensionality poorly.
UMAP
Out of the few dimensionality reduction algorithms, UMAP is arguably the best performing as it keeps a significant portion of the high-dimensional local structure in lower dimensionality.
Install the package with pip install umap-learn before we lower the dimensionality of the document embeddings. We reduce the dimensionality to 5 while keeping the size of the local neighborhood at 15. You can play around with these values to optimize for your topic creation. Note that a too low dimensionality results in a loss of information while a too high dimensionality results in poorer clustering results.

HDBSAN
After having reduced the dimensionality of the documents embeddings to 5, we can cluster the documents with HDBSCAN. HDBSCAN is a density-based algorithm that works quite well with UMAP since UMAP maintains a lot of local structure even in lower-dimensional space. Moreover, HDBSCAN does not force data points to clusters as it considers them outliers.
Install the package with pip install hdbscan then create the clusters:

NOTE: You could skip the dimensionality reduction step if you use a clustering algorithm that can handle high dimensionality like a cosine-based k-Means.
4. Topic Creation
This can be done with a class-based variant of TF-IDF (c-TF-IDF), that would allow us to extract what makes each set of documents unique compared to the other.
The intuition behind the method is as follows. When you apply TF-IDF as usual on a set of documents, what you are basically doing is comparing the importance of words between documents.
Here, we will treat all documents as a single document and then apply TF-IDF. The result would be a very long document per cluster and the resulting TF-IDF score would demonstrate the important words in each cluster.
c-TF-IDF
To create this class-based TF-IDF score, we need to first create a single document for each cluster of documents:

Then, we apply the class-based TF-IDF by joining documents within a class.
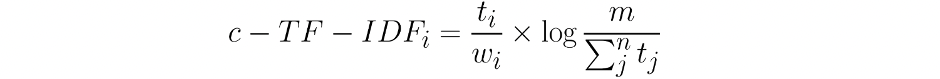
Where the frequency of each word t is extracted for each class i and divided by the total number of words w. This action can be seen as a form of regularization of frequent words in the class. Next, the total, unjoined, number of documents m is divided by the total frequency of word t across all classes n.

Now, we have a single importance value for each word in a cluster which can be used to create the topic. If we take the top 10 most important words in each cluster, then we would get a good representation of a cluster, and thereby a topic.
Topic Representation
In order to create a topic representation, we take the top 20 words per topic based on their c-TF-IDF scores. The higher the score, the more representative it should be of its topic as the score is a proxy of information density.

We can use topic_sizes to view how frequent certain topics are:

The topic name-1 refers to all documents that did not have any topics assigned. The great thing about HDBSCAN is that not all documents are forced towards a certain cluster. If no cluster could be found, then it is simply an outlier.
We can see that topics 7, 43, 12, and 41 are the largest clusters that we could create. To view the words belonging to those topics, we can simply use the dictionary top_n_words to access these topics:


